


什么是有象大数据平台?
在DT时代的今天,各行各业在产生着海量结构多样的数据。传统数据库技术已无法满足高效处理这些数据、挖掘潜在价值的要求。
有象大数据平台应运而生,全面解决多源异构数据管理、存储、运算与输出问题,帮助用户构建海量数据管理系统,发现数据内在
价值,助力业务发展。
有象大数据平台应运而生,全面解决多源异构数据管理、存储、运算与输出问题,帮助用户构建海量数据管理系统,发现数据内在
价值,助力业务发展。
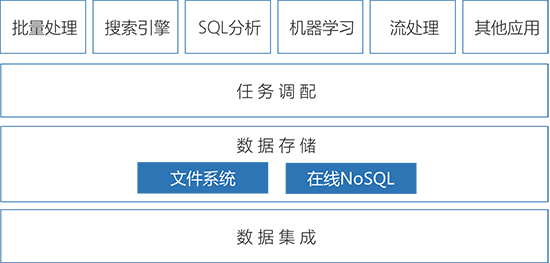
有象大数据平台能解决什么问题?
 数据管理
数据管理
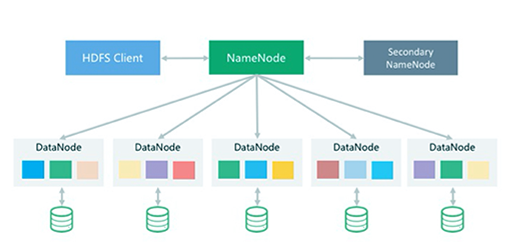
汇聚海量异构数据源,自动化统一管理

将不同业务系统中分散、零乱、标准不一的各种源数据中的
数据进行汇聚。支持从互联网、物联网、企业内部系统等各
种数据源中提取数据。各类数据的抽取、清洗和转化由统一
操作接口封装,可实现自动化地、分布式地执行整个ETL作
业。
数据进行汇聚。支持从互联网、物联网、企业内部系统等各
种数据源中提取数据。各类数据的抽取、清洗和转化由统一
操作接口封装,可实现自动化地、分布式地执行整个ETL作
业。
数据存储
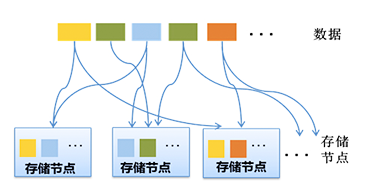
突破传统IT海量数据存储限制,提供安全、快速、可扩展的新一代解决方案
安全:传统存储架构需要有单独的备份方案,容错性低;有
象大数据平台多节点分布式架构保证文件安全。
查询快:面对海量异构数据,传统关系型数据库面临查询慢
的问题;有象大数据平台可以传统SQL的查询方式自由穿行
于海量数据间。
象大数据平台多节点分布式架构保证文件安全。
查询快:面对海量异构数据,传统关系型数据库面临查询慢
的问题;有象大数据平台可以传统SQL的查询方式自由穿行
于海量数据间。
可扩展:传统存储架构可扩展存储空间有上限,无法满足海量数据存储需求;有象大数据平台可动态
扩展存储能力和计算能力。
扩展存储能力和计算能力。
数据运算
高性价比分布式集群,提供高性能数据运算引擎
兼容性:同时支持Map Reduce和Spark
速度快:分布式架构使快速处理海量数据成为可能
多场景:同时支持离线运算和实时运算
高吞吐:可支持海量数据高并发处理
生态化:内置多种组件,快速应用于不同场景
速度快:分布式架构使快速处理海量数据成为可能
多场景:同时支持离线运算和实时运算
高吞吐:可支持海量数据高并发处理
生态化:内置多种组件,快速应用于不同场景
数据输出
数据存储与获取采用分布式架构,可无限水平延展
多种数据类型文件:关系型与非关系型数
据库均适用;CSV,Json,MySQL,
Excel格式任选择
无缝对接Sqoop数据系统
内置数据清洗模块,快速推进建模流程
据库均适用;CSV,Json,MySQL,
Excel格式任选择
无缝对接Sqoop数据系统
内置数据清洗模块,快速推进建模流程
构建基于海量数据的数据仓库:使业务人员操作大数据平台成为可能,简单学习SQL语句即可操作
可视化运维管理
Web图形化界面,平台管理更轻松
快速部署
性能监测
集群管理
组件安装
故障报警
权限管理
性能监测
集群管理
组件安装
故障报警
权限管理



准备好开始大数据升级了吗?
联系我们


